Zig is interesting language for low level programming and I figured the best way how to learn it is to build something. Inspired by blog post I will try to beat the One billion rows challenge with it. It’s not going to be easy since Rust is the closest thing I’ve programmed in and even tho in some ways it’s close, zig is probably closer to C then to Rust. So let’s get to it
Baseline
This baseline implementation took me way too long. Zig is really strict about correctly managing memory and I’m not used to do it. Coming from languages with runtime to manage memory like go it’s so foreign to me to manage my own memory and to free it after it’s not needed anymore. It was especially hard with the hashmap where the key is actually a pointer to the key and you have to keep the key allocated the whole lifetime of the hashmap. And this was just so hard and I still don’t think my solution is even correct. This is probably going to be something I will be battling with in future iterations especially since I want to introduce threading. Anyway this is just simple line by line reading and parsing of the input. Nothing special and apart from the use of allocator and little bit of pointer passing, the code is pretty readable and comparable with something I would write in any other language.
const std = @import("std");
const split = std.mem.splitAny;
const fs = std.fs;
const print = std.debug.print;
const assert = std.debug.assert;
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
const args = try std.process.argsAlloc(allocator);
defer std.process.argsFree(allocator, args);
const file = try fs.cwd().openFile("measurements.txt", .{});
defer file.close();
var buf_reader = std.io.bufferedReader(file.reader());
const reader = buf_reader.reader();
var line_no: usize = 1;
var line = std.ArrayList(u8).init(allocator);
defer line.deinit();
const writer = line.writer();
var ln = try Line.init(allocator);
defer ln.deinit();
const buf = try allocator.alloc(u8, 4096 * 2);
defer allocator.free(buf);
var city_map = std.StringHashMap(City).init(allocator);
defer city_map.deinit();
while (reader.streamUntilDelimiter(writer, '\n', null)) : (line_no += 1) {
defer line.clearRetainingCapacity();
try parseLine(&ln, line.items);
const key = try allocator.dupe(u8, ln.name);
const city = try city_map.getOrPut(key);
if (city.found_existing) {
city.value_ptr.*.addItem(ln.temp);
} else {
city.value_ptr.* = City{
.min = ln.temp,
.max = ln.temp,
.sum = ln.temp,
.count = 1,
};
}
if (city.found_existing) {
defer allocator.free(key);
}
} else |err| switch (err) {
error.EndOfStream => {}, // Continue on
else => return err, // Propagate error
}
const cities = try allocator.alloc([]const u8, city_map.count());
defer allocator.free(cities);
var iter = city_map.keyIterator();
var i: usize = 0;
while (iter.next()) |k| {
cities[i] = k.*;
i += 1;
}
std.mem.sortUnstable([]const u8, cities, {}, strLessThan);
for (cities) |c| {
const city = city_map.get(c) orelse continue;
const count: f64 = @floatFromInt(city.count);
print("{s} min: {d}, max: {d}, avg: {d}\n", .{ c, city.min, city.max, city.sum / count });
}
// cleanup
iter = city_map.keyIterator();
while (iter.next()) |k| {
allocator.free(k.*);
}
}
fn strLessThan(_: void, a: []const u8, b: []const u8) bool {
return std.mem.order(u8, a, b) == std.math.Order.lt;
}
const City = struct {
const Self = @This();
min: f64,
max: f64,
sum: f64,
count: i64,
pub fn addItem(self: *Self, item: f64) void {
self.min = @min(self.min, item);
self.max = @max(self.max, item);
self.sum += item;
self.count += 1;
}
};
const Line = struct {
const Self = @This();
name: []u8,
temp: f64,
allocator: std.mem.Allocator,
fn init(allocator: std.mem.Allocator) !Line {
const name = try allocator.alloc(u8, 0);
return Line{
.name = name,
.temp = 0,
.allocator = allocator,
};
}
fn set_name(self: *Self, n: []const u8) !void {
const name = try self.allocator.realloc(self.name, n.len);
@memcpy(name, n);
self.name = name;
}
fn deinit(self: Self) void {
self.allocator.free(self.name);
}
};
// This is missing input checking intentionally
fn parseLine(ln: *Line, line: []const u8) !void {
var s = split(u8, line, ";");
var i: u8 = 0;
while (s.next()) |l| {
switch (i) {
0 => {
try ln.set_name(l);
},
1 => {
const temp = try std.fmt.parseFloat(f64, l);
ln.temp = temp;
},
99 => break,
else => break,
}
i += 1;
}
}
For me the interesting part is the parseLine function that takes different approach then how I would normally write it in go. This is because of the memory management. In go i would write something like:
func parseLine(line string) (*Line, error){
s := strings.Split(line, ";");
temp, err := strconv.ParseFloat(s[1], 64)
if err != nil {
return nil, err
}
return &Line{
Name: s[0],
Temp: temp,
}, nil
}
This is of course simplified and without runtime checks. But the point is I’m creating memory inside the function and then leaking it outside of the function context. This is usually fine, but zig forces you to think about the memory and I think that’s powerful. Programming more zig will probably effect all of my code and subsequently make it more performant. If in the go example I would create the struct outside of the function and then passed the pointer in, the runtime would be more inclined to allocate the struct on stack instead of leaking it onto heap.
The baseline runs slow, slow enough I was impatient to wait for it to finish, however it would take few hours to finish.
Allocation
Profiling the program revealed that the Stack trace of allocator being slowdupe function is about half of the call stacks.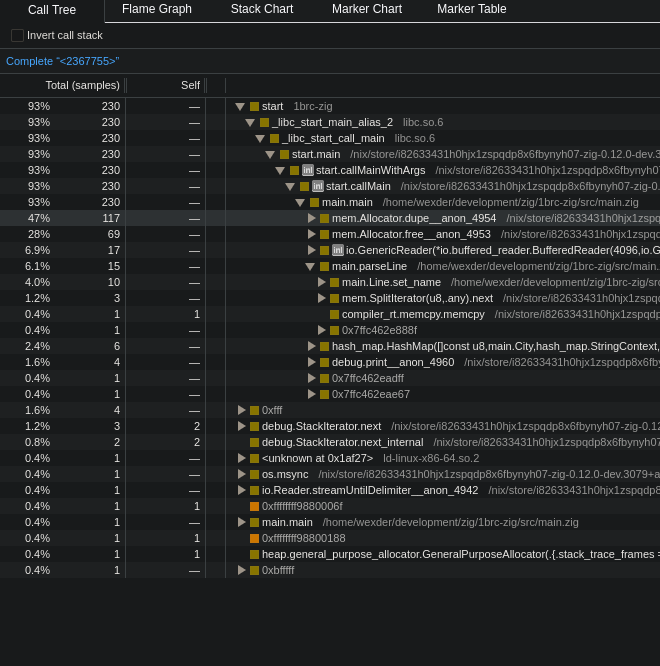
dupe is called to create a key so we can use pointer to it in the map, and the pointer has to be valid basically until the end of the program.
I tried to reuse the name from the parsed line, but will not work as the field is overwritten every iteration ie. every line. After some searching around and thinking about the problem the fix was quite easy.
Problem is in constant allocation and deallocation, and even tho it can sound odd, allocation of memory is expensive operation. That’s because your program have to ask the operating system for the memory, and that takes some time.
To fix this I simply wrapped the allocator in ArenaAllocator, like so.
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
var arena = std.heap.ArenaAllocator.init(gpa.allocator());
defer arena.deinit();
const allocator = arena.allocator();
The arena allocator simple pretends to free the memory but it actually does not return it to the memory to the OS. At least that’s how I understand it. Side effect of using the arena allocator is that we now don’t have to cleanup the keys, instead they all will be freed with the arena allocator, making the code little cleaner.
We still want to free the keys when they are not used otherwise our program would explode in memory usage.
I was also surprised how little the parseLine is compared to the rest of the program, for now.
With arena allocator I can parse the billion rows in about 35 minutes that’s about 500 000 rows per second, not bad if you ask me, but I can do better.
One part of the program optimized let’s get to other problems.
Reading
Second problem is reading the file itself. Currently I’m using basic sequential reading of the file. Disk I/O slowing down the program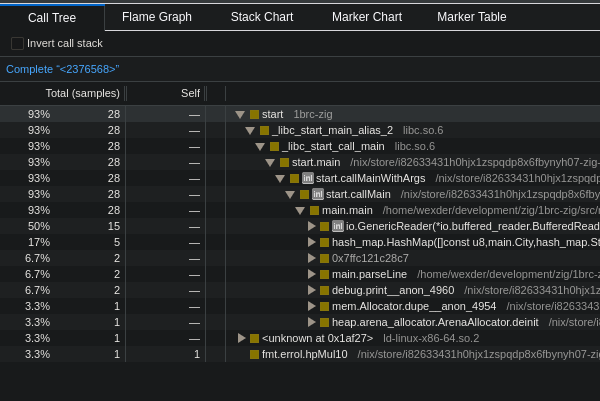
mmap.
I’m probably not smart enough to explain mmap in detail, but basically it maps the file into virtual memory. It allows much faster access to the file.
Code changes are quite straight forward, after we open the file we need to know the size. With that we can request our OS to map the file into virtual memory and we will get back the content in form of u8 slice.
const file_len: usize = std.math.cast(usize, try file.getEndPos()) orelse std.math.maxInt(usize);
const mapped_mem = try std.os.mmap(
null,
file_len,
std.os.PROT.READ,
.{ .TYPE = .PRIVATE },
file.handle,
0,
);
defer std.os.munmap(mapped_mem);
With this change we decrease the execution time to around 11 minutes. Still long time but it’s almost 1.5 million lines parsed per second.
Profiling the program again now shows interesting results. The Stack trace after mmapdupe function is back to about 13% of the call stack, the rest is pretty much taken by parseLine and HashMap.getOrPut.parseLine was expected but what I didn’t expect the getOrPut, but digging deeper it started to make a little bit of sense. The most time spend in getOrPut is in the hash function of the hash map.
Also the map gets quite big closer to the end of the run.
So far the program run only on one core but most machines have more then that, but before we get to Multithreading let’s try to remove the need for dupe all together.
Since mmap returns basically string, we can slice it and use that as key to the map. And since the mmap data lives for the whole duration of the program, we don’t have to worry about seg faults.
So instead of copying the data from mmap to be set in Line struct and the duping it to use it as key. I can take the length of the name and construct key as:
const key = mapped_mem[last_n .. last_n + ln.name_length];
This gets rid of any expensive memory allocation inside the parsing loop and bringing the time low as 7 minutes.
Since I know the input will always be correct I can also refactor the parseLine function a little bit, getting rid of the split function.
fn parseLine(ln: *Line, line: []const u8) !void {
for (line, 0..) |l, i| {
if (l == ';') {
ln.name_length = i - 1;
const temp = try simpleFloatParse(line[i..]);
ln.temp = temp;
}
}
}
This further reduced the time to about 5 minutes 30 seconds.
Multithreading
As most of modern programming languages are using lightweight threads and have some kind of async runtime, it’s not so common anymore for backend developer to touch actual OS threads. Zig currently (as of version 0.12) have only experimental support of async but I want to use thread anyway. I split the workload to two parts. Main thread reading from the file and worker thread which will be spawned and receive slices to work on. The biggest obstacle I faced was the communication between the main thread and the worker thread, because zig don’t have any primitives to do this easily. In go I would setup channel to send back results from worker thread (goroutine in go) to main one. In zig I had the idea to create HashMap in the main thread and pass pointer to it to the worker thread, but I couldn’t get it working. It was either passing the pointer as const so I couldn’t write to it, or I was getting segmentation faults. I’m sure this was skill issue and can be easily done, but I to get inspired by candrewlee14 which was kinda my reference for implementation more about that later. So this is the params I decided to pass into the worker thread:
const WorkerCtx = struct {
city_map: *std.StringHashMap(City),
};
fn threadRun(
allocator: std.mem.Allocator,
mapped_mem: []u8,
wg: *std.Thread.WaitGroup,
ctx: *WorkerCtx,
lock: *std.Thread.Mutex,
) void {
I’m reusing the arena allocator we already talked about. Then as the most important I’m passing slice of the mmaped memory slice, this is basically just chunk of the file.
Interestingly enough zig has WaitGroup that’s similar to golang, so I will use that for tracking if all of the threads finished their work.
So synchronization of the parsed data I’m passing ctx and corresponding lock to it. The context just have the “main” map of results. The implementation of the threadRun is just our main loop for parsing line by line.
defer wg.finish();
var ln = try Line.init();
defer ln.deinit();
var city_map = std.StringHashMap(City).init(allocator);
defer city_map.deinit();
var last_n: u64 = 0;
for (mapped_mem, 0..) |b, i| {
if (b == '\n') {
parseLine(&ln, mapped_mem[last_n..i]) catch break;
const key = mapped_mem[last_n .. last_n + ln.name_length];
const city = city_map.getOrPut(key) catch break;
if (city.found_existing) {
city.value_ptr.*.addItem(ln.temp);
} else {
city.value_ptr.* = City{
.min = ln.temp,
.max = ln.temp,
.sum = ln.temp,
.count = 1,
};
}
last_n = i + 1;
}
}
var iter = city_map.iterator();
lock.lock();
while (iter.next()) |kv| {
const city = ctx.city_map.getOrPut(kv.key_ptr.*) catch return;
if (city.found_existing) {
city.value_ptr.*.merge(kv.value_ptr);
} else {
city.value_ptr.* = kv.value_ptr.*;
}
}
lock.unlock();
The only difference here is that each thread creates it’s own temporary map to which I parse the chunk and after that merge it into the “main” context. To prevent simultaneous mutation I’ve added mutex. I was happy to get this working but still I would like to explore better solutions for returning results from the threads that are easier to work with. I’m planning to explore zig more by writing http server, so that’s going to be a good place to explore threads more.
After I’ve implemented this I thought I would be done, but the script still run for 19 seconds. I was happy I was able to write something so fast in language I knew nothing about 2 days ago, but disappointed since I was expecting like maybe 10s.
Candrewlee14’s implementation I was referencing ran only for about 6 seconds, I knew I wouldn’t be able to write it as good, but 3x the time was still disappointment.
Profiling the code it didn’t seemed that my code was the issue, or at least I didn’t saw anything in the call tree. I scratched my brain for some time and then I noticed the weird cpu utilization on each thread. Stack trace after mmap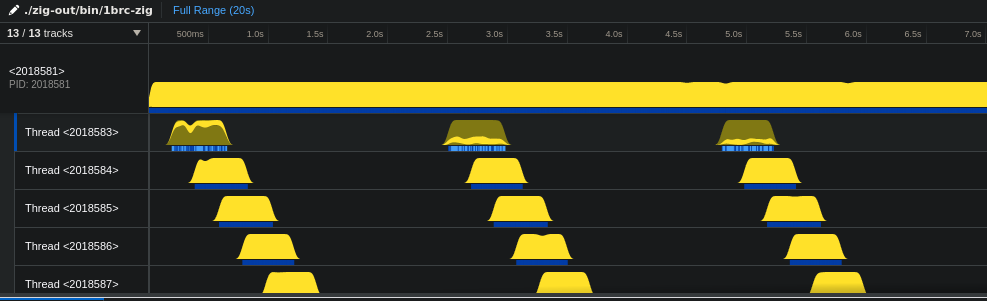
Going through the my reference I noticed only one difference. The use of std.mem.indexOfScalarPos(u8, mapped_mem, search_start, '\n') instead of iterating through the mapped_mem and comparing if current character is new line.
But why would this be faster ?
SIMD
Turns out the answer why was their implementation faster is SIMD and more optimized splitting to chunks. My implementation original iterated through the slice until I had enough lines to spawn the thread and this turned out to be highly wasteful.
To speed it up I take inspiration and shamelesssly copied candrewlee14’s code that split almost evenly the mapped_mem slice by number of CPU cores and then seeking next new line by using mentioned indexOfScalarPos.
The interesting part for me was that it uses SIMD instructions to do comparison of multiple characters in stead of one by one. I thought SIMD was only useful for mathematical operations, but it turned out there are even json parsers sped up by using SIMD.
As interesting as it would be to know enough about SIMD to be able to explain how it actually works, I definitely don’t, but maybe one day. If you are interested to read more simdjson
repository is good start.
Finally after implementing all of this and admittedly cheating a little bit I’ve reached 6s.
Conclusion
Eve tho I just spoiled most of the optimizations you can use I recommend everyone to try this challenge. Each time you take down little bit of time it’s satisfying and you can learn so much. It’s also great exercise to try to do in new language. And you will get perspective of just how much one billion of anything is. When it comes to zig, this was my first code I wrote after completing zigling, and I want to explore it more. The lack of string type scared me at first, but thinking about strings just as slices gives them really interesting perspective. And it’s probably the basic concept of zero allocation parsers (I still don’t get this concept fully). I like being able to explore the low level concepts abstracted out in higher level languages. I think it’s already noticeable how my thinking about the program changed through out the writing of this. As each part of text was written after I wrote the implementation. Code for final implementation can be found here